Open source model of apple roll, open code, weight, data set and training process, OpenELM appeared.
Machine heart report
Editor: Chen Ping, saute spicy chicken
Apple released OpenELM, an efficient language model family based on open source training and reasoning framework.
If ChatGPT started the big model competition, then the Meta open source Llama series models set off a craze in the open source field. Among them, the apple doesn’t seem to make a big splash.
However, in the latest paper released by Apple, we can see its contribution in the field of open source.
Recently, Apple released OpenELM with four variants (parameters are 270M, 450M, 1.1B and 3B respectively), which is a series of pre-training and fine-tuning models based on public data sets. The core of OpenELM is layer-by-layer scaling, that is, each Transformer layer in OpenELM has a different configuration (for example, the number of heads and the dimension of feedforward network), which leads to the different number of parameters in each layer of the model, thus achieving more effective cross-layer parameter allocation.
It is worth mentioning that Apple released a complete framework this time, including data preparation, training, fine-tuning and evaluation procedures, as well as a number of pre-trained checkpoint and training logs to promote open source research.

Address: https://arxiv.org/pdf/2404.14619.pdf.
Project address: https://github.com/apple/corenet.
Paper title: open elm: an efficient language model family with open-source training and influence framework.
The results show that the performance of OpenELM is better than the existing open source LLM which is pre-trained with public data sets (Table 1). For example, OpenELM with 1.1 billion parameters outperforms OLMo.

Method introduction
OpenELM architecture
OpenELM adopts transformer architecture with only decoder, and follows the following ways:
(1) Do not use learnable deviation parameters in any fully connected (also called linear) layer;
(2) using RMSNorm for pre-standardization, and rotating position ROPE is used to encode position information;
(3) Use grouped query attention (GQA) instead of multi-head attention (MHA);
(4) replace the feedforward network (FFN) with SwiGLU FFN;
(5) using flash attention to calculate the scalable dot product attention;
(6) Use the same tokenizer as LLama.
Generally speaking, each transformer layer in LLM uses the same configuration, thus realizing the uniform distribution of cross-layer parameters. Different from these models, each Transformer layer in OpenELM has a different configuration (for example, the number of heads and the dimension of feedforward network), which leads to different parameters in each layer of the model. This enables OpenELM to make better use of the available parameter budget to achieve higher accuracy. Apple uses layer-wise scaling to realize the uneven distribution of cross-layer parameters.
Scaling layer by layer: The standard Transformer layer consists of multi-head attention (MHA) and feedforward network (FFN). In order to solve the problem of uneven distribution of parameters in Transformer layer, Apple adjusted the number of attention heads and FFN multipliers in each Transformer layer.
Apple does this. Suppose that the standard Transformer model with uniform parameter distribution has n layers of transformers, and the input dimension of each layer is d_model. MHA has n_h headers, and the dimension of each header is
, the hidden dimension of FFN is:
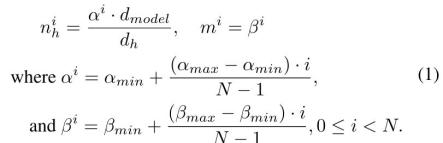
Apple introduced two superparameters, α and β, to scale the number of attention heads n_h and m in each layer respectively. For layer I, n_h and m are calculated as:
Pre-training data
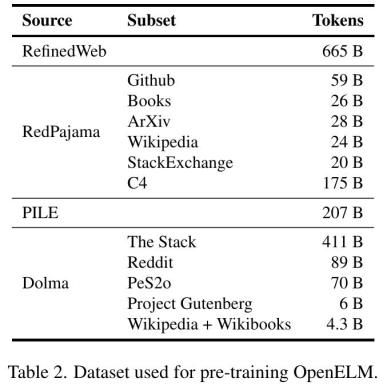
For pre-training, Apple uses public data sets. Specifically, their pre-training data set includes a subset of RefinedWeb, deduplicated PILE, RedPajama and a subset of Dolma v1.6, totaling about 1.8 trillion token. As shown in the following table.
Training details
Apple used its own open source CoreNet library (formerly known as CVNets, specially used for training deep neural networks) to train OpenELM variants, and the training process was iterated for 350,000 times. Finally, four variants of OpenELM are trained (parameters are 270M, 450M, 1.1B and 3B).
experiment
In this paper, the performance of OpenELM is evaluated under zero sample and few sample settings, as shown in Table 3. The researchers compared OpenELM with the published LLM, including PyThia, Cerebras-GPT, TinyLlama, OpenLM, MobiLlama and OLMo. Related to the work of this paper are MobiLlama and OLMo. These models are all trained on similar data sets and have similar or more pre-training token.
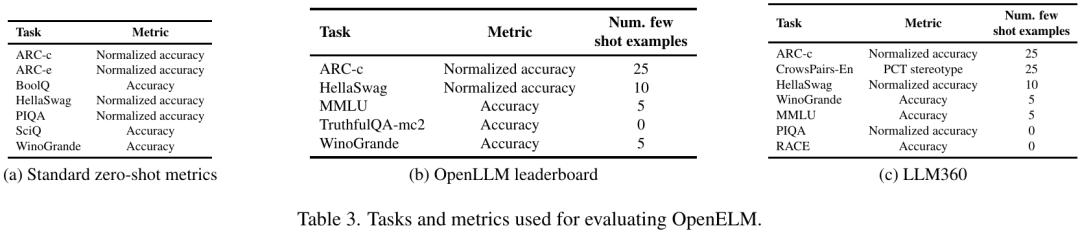
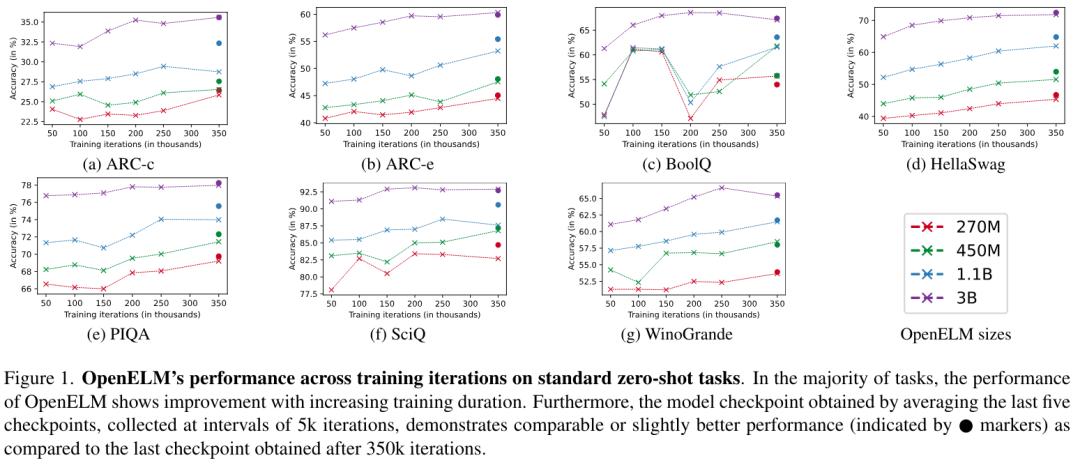
Figure 1 plots the accuracy of OpenELM with the number of training iterations on seven standard zero-sample tasks. It can be found that in most tasks, with the extension of training duration, the accuracy will be improved on the whole. In addition, the accuracy of the checkpoints obtained by averaging the last five checkpoints (collected once every 5000 iterations) is equivalent to or slightly improved by the final checkpoints obtained after 350k iterations. This improvement is probably due to the fact that the average weight reduces the noise. Therefore, in the main evaluation in Table 4, the instruction tuning experiment in Table 5 and the parameter efficiency tuning experiment in Table 6, the researchers used the average checkpoint.
The results in Table 4 span various evaluation frameworks, highlighting the effectiveness of OpenELM compared with existing methods. The results in Table 4 span different evaluation frameworks, highlighting the effectiveness of OpenELM compared with existing methods. For example, compared with OLMo with 1.2 billion parameters, the accuracy of OpenELM with 1.1 billion parameters is improved by 1.28% (Table 4a), 2.36% (Table 4b) and 1.72% (Table 4c), respectively. It is worth noting that OpenELM achieved such accuracy, but used much less pre-training data than OLMo.
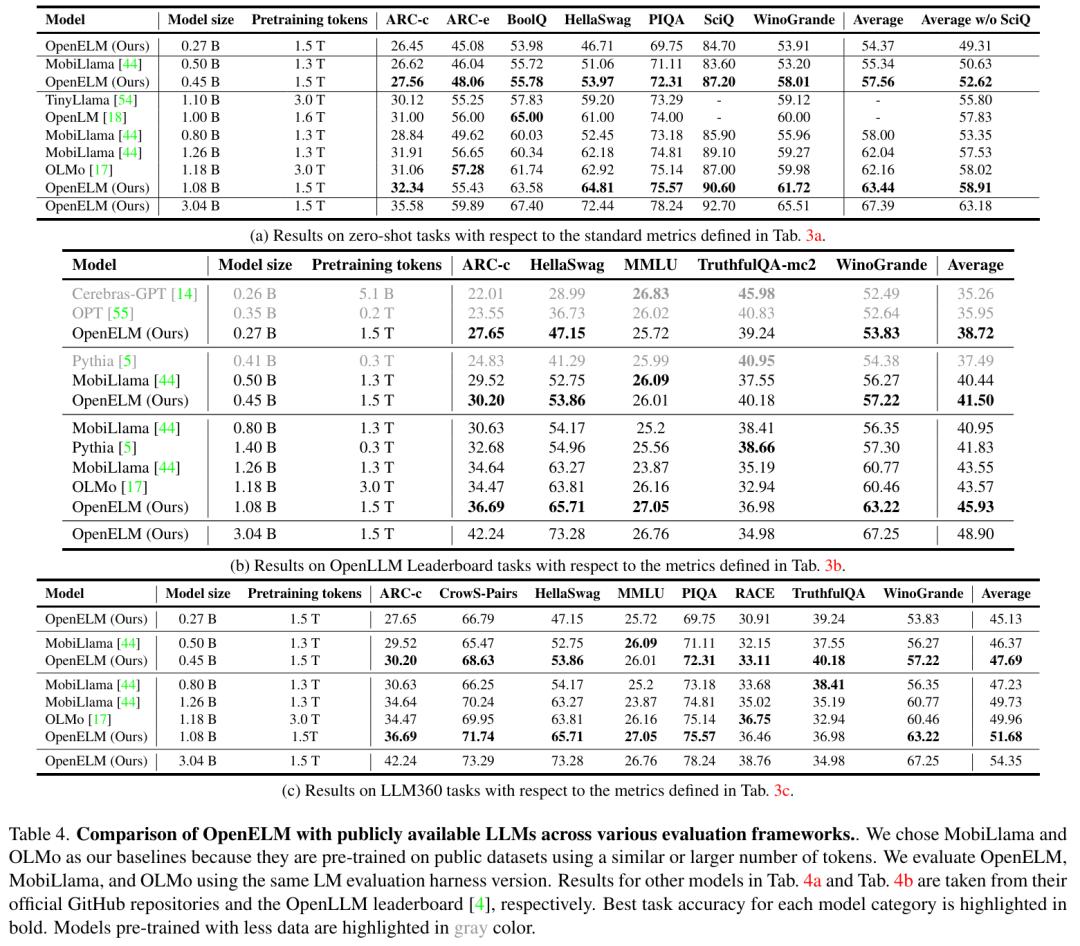
As shown in Figure 5, in different evaluation frameworks, instruction fine-tuning can always improve the average accuracy of OpenELM by 1-2%.
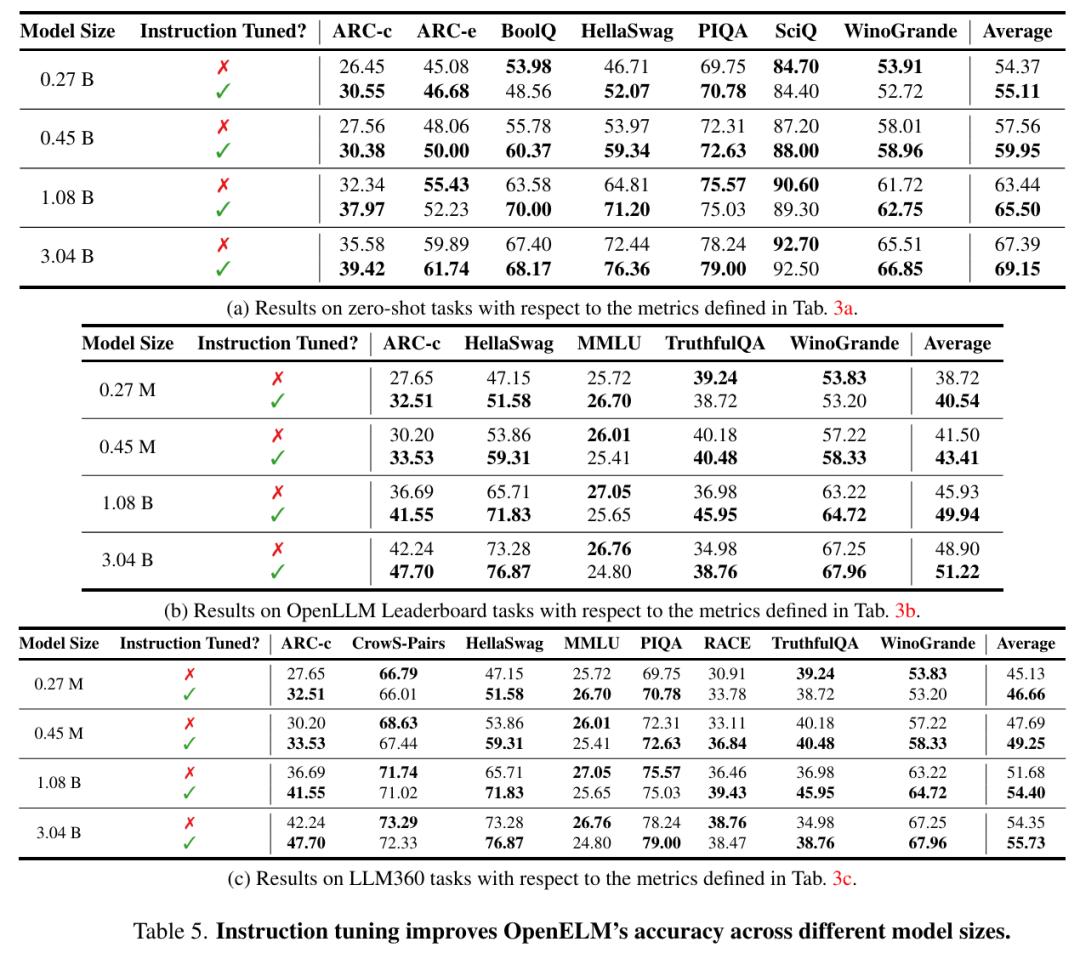
Efficient fine tuning of parameters (PEFT) results. Training and evaluation settings for researchers to use common sense reasoning. This setting provides eight 170k training samples of multiple-choice data sets for different methods to study PEFT, including LoRA and DoRA. The researchers integrated OpenELM with these methods, and used eight NVIDIA H100 GPU to fine-tune the generated model for three training cycles. As shown in Table 6, the PEFT method can be applied to OpenELM. On the given CommonSense inference data set, the average accuracy of LoRA and DoRA is similar.
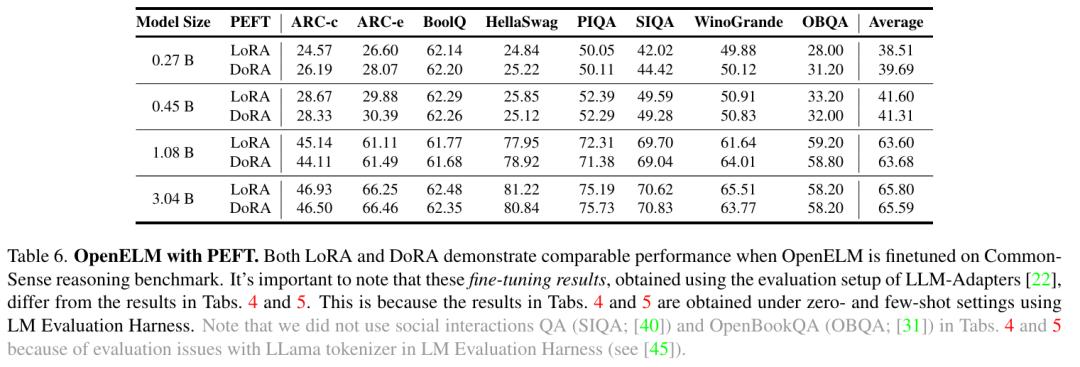
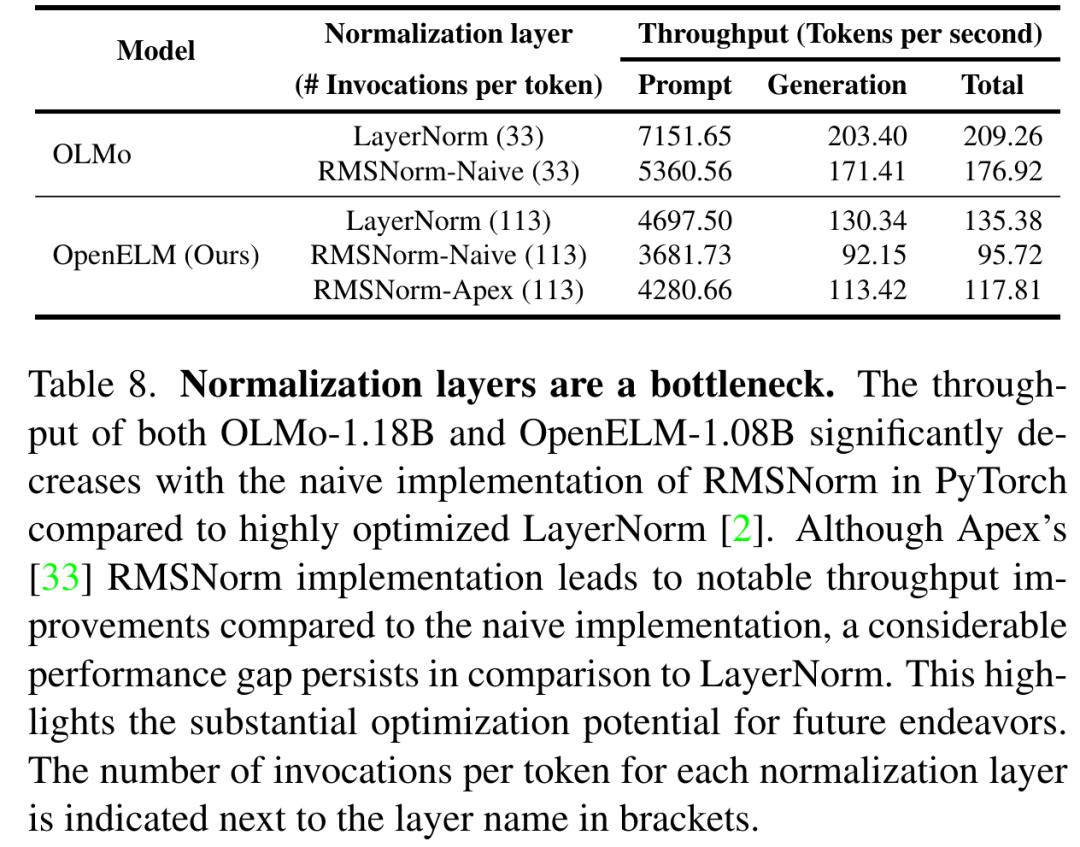
Tables 7a and 7b show the benchmark test results of this work on GPU and MacBook Pro respectively. Although OpenELM is more accurate with similar parameters, its speed is slower than OLMo. Although the main focus of this study is reproducibility rather than reasoning performance, the researcher has conducted a comprehensive performance analysis to determine the bottleneck of the work.
The analysis shows that a considerable part of OpenELM’s processing time can be attributed to the researchers’ simple implementation of RMSNorm (see Table 8). In detail, that is, a simple RMSNorm implementation leads to many separate kernels starting, each processing a small amount of input, instead of starting a single fusion kernel like LayerNorm. By replacing the simple RMSNorm with Apex’s RMSNorm, the researchers found that the throughput of OpenELM was significantly improved. However, compared with the model using optimized LayerNorm, there is still a significant performance gap, partly because (1)OpenELM has 113 layers of RMSNorm, while OLMo has 33 layers of layer norm; (2) The RMSNorm of 2)Apex is not optimized for small input. In order to further illustrate the performance degradation caused by RMSNorm, Apple replaced the LayerNorm in OLMo with RMSNorm, and observed that the generation throughput decreased significantly. In the future work, researchers plan to explore optimization strategies to further improve the reasoning efficiency of OpenELM.
Original title: "Apple Roll Open Source Model, Open Code, Weight, Data Set, Training Process, OpenELM Debut"
Read the original text